
یادگیری ماشین یا Machine learning که به اختصار با ML نمایش داده می شود، یکی از زیر شاخه های هوش مصنوعی است و بر این اساس، با الگوبرداری از داده ها و تصمیم گیری (با کمی دخالت انسان) کار می کند.
سیستمی که بر اساس مشاهدات و علایق کاربران، در سایت هایی همچون آمازون و نتفلیکس، به آنها پیشنهاد محصولات جدید می دهد نمونه ای از یادگیری ماشین است. سیستم هایی که ایمیل های اسپم و کامنت هایی با محتوای نامناسب را فیلتر کرده و یا تراکنش های بانکی مشکوک را شناسایی می کنند، نمونه های مهم دیگری از کاربرد یادگیری ماشین در دنیای امروز هستند.
یادگیری ماشین به چه معناست؟
در حالی که هوش مصنوعی (AI) یک علم گسترده است و با هدف تقلید از توانایی های انسان ایجاد شده، یادگیری ماشین (ML) یکی از زیرمجموعه های هوش مصنوعی است که ماشین یا کامپیوتر را برای یادگیری تربیت می کند.
یادگیری ماشین یا ML یکی از روش های تحلیل و آنالیز داده است که مدل تحلیلی ایجاد شده را خودکار می کند. در نتیجه زمانی که مدل در معرض داده های جدید قرار می گیرد، می تواند به صورت مستقل و با دانشی که از داده های قبلی به دست آورده، سازگار شود و برای داده های آینده پیش بینی کند.
یادگیری ماشین به شیوه ای که امروزه آن را می شناسیم، از این ایده متولد شده است که کامپیوترها با تشخیص الگوها و بدون آنکه برنامه نویسی پیشرفته ای برای آنها انجام شود، بتوانند یاد بگیرند و وظایف خاصی را انجام دهند.
بسیاری از الگوریتم هایی که در یادگیری ماشین استفاده می شوند (مانند رگرسیون) سابقه طولانی دارند، اما توانایی ترکیب سریع و چندین باره مفاهیم ریاضی با داده های فراوانی که امروزه در دسترس ما قرار دارد، دستاوردی جدید محسوب می شود.

یادگیری ماشین با چه روش هایی انجام می شود؟
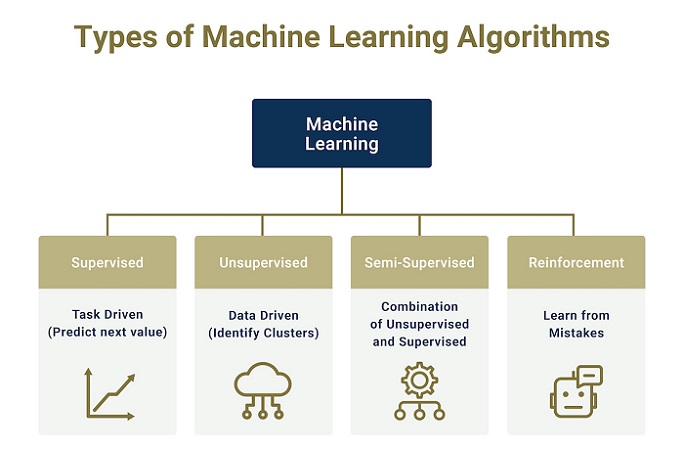
یادگیری ماشین به روش کلاسیک و بر مبنای نحوه یادگیری الگوریتم مدل سازی برای پیش بینی دقیق تر، در چهار دسته اساسی طبقه بندی می شود. هر کدام از الگوریتم های زیر، بر مبنای نوع داده ای که قرار است پیش بینی شود، انتخاب و استفاده می شوند.
1- یادگیری نظارت شده
در این نوع از یادگیری ماشین، سیستم از الگوریتمی که در گذشته از داده های با لیبل یا برچسب گذاری شده آموخته است، استفاده می کند تا با اعمال آن الگوریتم روی داده های جدید، وضعیت داده های آینده را پیش بینی کند.
برای ایجاد تابعی که الگوریتم پیش بینی بر مبنای آن ایجاد می شود، از تحلیل داده های آموزشی (داده هایی که از صحت آنها اطمینان داریم) استفاده می شود.
بعد از آموزش، سیستم می تواند از هر دسته داده جدید، خروجی مورد نظر را ایجاد کند و با مقایسه خروجی خود با جواب صحیح و مورد انتظار، خطاهای خود را پیدا کرده و مدل را اصلاح کند. در یادگیری نظارت شده کنترل بیشتری روی سیستم وجود دارد و سوگیری سیستم نسبت به روش های دیگر، کمتر است.
داده های لیبل دار در واقع داده ها و اطلاعاتی هستند که نوع و ویژگی آنها مشخص شده است. فرض کنید ما اطلاعات و ویژگی های تعدادی خانه را به سیستم می دهیم. این ویژگی ها شامل متراژ، تعداد اتاق و… هستند. از طرفی قیمت هر کدام از این خانه ها را هم به سیستم می دهیم. حالا سیستم یک الگو میان ویژگی های یک خانه و قیمت آن تعیین می کند. در نتیجه ما می توانیم با دادن اطلاعات یک خانه جدید به سیستم، قیمت آن را به دست آوریم. در این مثال قیمت خانه، همان برچسب داده است. در واقع در یادگیری نظارت شده، سیستم می داند که قرار است چه چیزی را به دست آورد.
یادگیری نظارت شده برای انجام وظایف زیر استفاده می شود:
- طبقه بندی صفر و یکی یا Binary classification: برای تقسیم کردن داده ها به دو دسته متفاوت
- طبقه بندی چند کلاسه یا Multi-class classification: برای انتخاب از میان چندین پاسخ (بیشتر از دو پاسخ)
- مدل سازی رگرسیون یا Regression modeling: برای پیش بینی مقادیر پیوسته
- یکپارچه سازی یا Ensembling: برای ترکیب پیش بینی چندین مدل یادگیری ماشین جهت تولید یک پیش بینی دقیق
2- یادگیری بدون نظارت
یادگیری بدون ناظر زمانی استفاده می شود که اطلاعات و داده ها طبقه بندی نشده اند و لیبل ندارند. در این نوع از یادگیری، ماشین تلاش می کند که تابعی برای توصیف ساختار پنهان داده های بدون برچسب ایجاد کند. در واقع بر خلاف مثال قبل که با وجود قیمت خانه ها داده ها لیبل دار بودند، در یادگیری بدون نظارت به سیستم نمی گوییم که چه خروجی باید ایجاد کند. در نتیجه خود سیستم از مجموعه داده هایی که در اختیار دارد استنباط می کند که خروجی باید چه چیزی باشد.
یادگیری بدون نظارت برای انجام وظایف زیر استفاده می شود:
- خوشه بندی یا Clustering: برای تقسیم داده ها به گروه هایی که تشابه بیشتری با هم دارند.
- تشخیص ناهنجاری یا Anomaly detection: برای تشخیص داده های غیرعادی در یک مجموعه داده
- ارتباط کاوی یا Association mining: برای تشخیص دسته ای از آیتم هایی که اغلب با هم و در یک مجموعه داده اتفاق می افتند.
- کاهش ابعاد یا Dimensionality reduction: برای کاهش تعداد متغیرها در یک مجموعه داده
3- یادگیری شبه نظارت شده
یادگیری شبه نظارت شده ترکیبی از یادگیری نظارت شده و بدون نظارت است. در این نوع یادگیری ماشین، سیستم از مجموعه کوچکی از داده های برچسب خورده یا لیبل دار برای ایجاد مدل استفاده می کند و سپس از مدل ایجاد شده کمک می گیرد تا مجموعه بزرگی از داده های بدون برچسب را لیبل گذاری کند، یا اینکه داده ها را بدون برچسب تحلیل کند.
یادگیری شبه نظارت شده برای انجام وظایف زیر استفاده می شود:
- ترجمه ماشینی یا Machine translation: برای آموزش الگوریتم های ترجمه، بدون نیاز به یک دیکشنری کامل و جامع
- تشخیص جعل یا Fraud detection: برای تشخیص موارد تقلب و جعل، زمانی که فقط چند نمونه مثال مثبت در دسترس باشد.
- برچسب گذاری داده ها یا Labelling data: برای آموزش سیستم بر اساس مجموعه ای از داده های برچسب دار و سپس استفاده از مدل ایجاد شده، برای برچسب دار کردن داده های بدون برچسب
4- یادگیری تقویت شده
در یادگیری تقویت شده، ماشین بر اساس پاداش دادن به رفتارهای مطلوب و تنبیه کردن رفتارهای نامطلوب، یاد می گیرد. در این نوع از یادگیری ماشین، سیستم قادر است تا محیط خود را درک و تفسیر کند و اقداماتی انجام دهد تا از طریق آزمون و خطا، یاد بگیرد که چطور باید رفتار کند و تشخیص دهد.
هدف سیستم در یادگیری تقویت شده آن است که در طولانی مدت میزان پاداش هایی که از انجام اعمال درست دریافت کرده است را به بیشترین حد خود برساند. در نتیجه با گذشت زمان، سیستم یاد می گیرد که از امتیازهای منفی دوری کند.
یادگیری تقویت شده برای انجام وظایف زیر استفاده می شود:
- رباتیک یا Robotics: برای آموزش وظایف دنیای فیزیکی به ربات ها
- گیم پلی ویدئویی یا Video gameplay: برای آموزش ربات ها جهت بازی با تعدادی از بازی های ویدئویی
- مدیریت منابع یا Resource management: برای بررسی نحوه تخصیص منابع مالی محدود یک شرکت برای یک هدف مشخص
کاربردهای علم یادگیری ماشین در جهان امروز
امروزه یادگیری ماشین کاربردهای گسترده ای در زندگی ما دارد. یکی از شناخته شده ترین کاربردهای ML، استفاده از آن در موتور پیشنهاد دهنده یا recommendation engine فیس بوک است. فیس بوک از این سیستم برای شخصی سازی اطلاعاتی که هر کاربر دریافت می کند، استفاده می نماید. اگر یک کاربر فیس بوک برای خواندن دسته خاصی از پست ها روی عناوین مشابه توقف کند، سیستم پیشنهاد دهنده عناوین مشابه دیگری را نیز به کاربر نمایش می دهد.
در واقع سیستم تلاش می کند تا الگوهای شناخته شده در رفتار کاربران آنلاین را تقویت کند. به محض آنکه کاربر، الگوی رفتاری خود را (در مشاهده گروه خاصی از پست ها) تغییر دهد، سیستم با این تغییر الگو منطبق شده و خبرهای دیگری که بر مبنای علایق جدید کاربر هستند را به او نشان می دهد.
نمونه های دیگری از کاربردهای ماشین لرنینگ عبارت اند از:
سیستم های مدیریت ارتباط با مشتری (CRM)
نرم افزارهای CRM از یادگیری ماشین برای تحلیل ایمیل ها استفاده می کنند و اعضای تیم فروش را ترغیب می کنند تا ابتدا به پیام های مهم پاسخ دهند. سیستم های پیشرفته تر حتی می توانند پاسخ های با تأثیرگذاری بیشتر را پیشنهاد دهند.
سیستم های اطلاعات منابع انسانی (HRIS)
سیستم های HRIS می توانند با استفاده از مدل های یادگیری ماشین، بهترین کاندیدای ممکن برای موقعیت های شغلی مورد نیاز شرکت ها را بر اساس توانایی و ویژگی های موجود در رزومه افراد فیلتر کنند.
یادگیری ماشین در دستیارهای مجازی
دستیارهای هوشمندی مانند siri دستیار اپل و دستیار مجازی گوگل، از ترکیب یادگیری ماشین نظارت شده و بدون نظارت برای تفسیر گفتار طبیعی و پاسخ به صورت متن استفاده می کنند.
ماشین های خودران
الگوریتم یادگیری ماشین، این امکان را برای ماشین های نیمه خودران فراهم می کند تا با تشخیص برخی از اشیا، به راننده هشدار دهد.
سخن آخر
یادگیری ماشین یا ML یکی از زیرشاخه های هوش مصنوعی (AI) است. در ML ماشین با دریافت تعداد زیادی داده و ایجاد یک مدل بر مبنای آن، به پیش بینی وضعیت داده هایی می پردازد که در آینده در دسترس او قرار می گیرد.
یادگیری ماشین بر اساس مدل سازی و ایجاد الگو به چهار دسته نظارت شده، بدون نظارت، شبه نظارت شده و تقویت شده تقسیم می شود که هر کدام برای الگوسازی دسته خاصی از داده ها و با هدف خاصی، استفاده می شوند.
یادگیری ماشین یک علم آزمایشگاهی نیست و تعداد زیادی از کمپانی ها برای افزایش بازده و ایجاد نوآوری، در سطوح پیشرفته ای از این دانش استفاده می کنند. در سال 2021 با همه گیر شدن ویروس کرونا، 41 درصد از شرکت ها به گسترش هوش مصنوعی و یادگیری ماشین در سیستم های خود سرعت دادند.




